
Note:
This post is based on our (Kuldeep and yours truly ) paper submitted in TACAS2019 and is currently a work in progress.
Currently some of the repositories might not be publicly available.
Prelude: What is (approximate) Model Counting?1
Given a Boolean formula, say $ \phi $, to to compute the number of solutions of $ \phi $ is called (Exact) Model Counting. But it turns out it’s NP-hard ( Actual it’s #P, which is a class of counting problems associated with decision problems, and therefore is harder than NP-complete problems because counting the solutions is definitely harder than identifying one ).
So theoretically we can’t even approximate a solution in general, but it turns out we can still approximate reasonable sized( with over 1000 variables) problems with present day SAT solvers, hence the name Approximate Model Counting.
The basic idea is this: Suppose you were to calculate the number of people in a large room. How would you do it as efficiently as possible. One obvious way is to simply count each person but that’s too costly ( $O(n)$ where $n$ is exponentially large ), it turns out there is a clever way to count by exploiting randomness( ask each person to get a coin ). Consider the following algorithm,
Every person starts with a hand up.
Everyone tosses a coin
If it's a head, keep your hand up
Else bring it down
Repeat till all hands are down.
Report 2^(number_of_rounds) as the estimate.
Observe that the above algorithm takes $O(\log(n))$ steps in expectation and returns the correct count with a high probability.
Now in practice this is achievedi(with some extra details) using a powerful mathematical tool called 2-Univerasal Hash Family , which is very good at dividing the solution space in small cells( each with a small number of elements), and a SAT solver which can (somewhat majically) count the number of cells with elements greater than some number (called the pivot, we usually set it to 72 ).
Now pivot $\times$ #number_of_cells gives the approximate count.
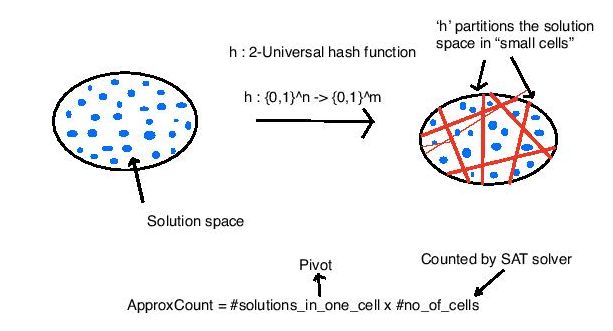 |
|---|
| Approximate Counting |
A word on XORs
 |
|---|
| XOR function |
Now hash function is actually implemented by adding XORs with density $p=\frac{1}{2}$. Thus on average XOR constraint size is $n/2$ where $n$ is number of variables.
Constraints with smaller size are friendlier to SAT solvers hence Zhao et al proposed a family of sparse hash functions with $p\le1/2$ (actually $\log(n)/n$ asymptotically)) to decrease the size of XOR constraints and hence make it easy for the SAT solver and hence decreasing the runtime of counter( they proposed an algorithm SparseCount, you can check out our implementation here ).
But it turns out if we use sparse families then we loose the gurantees on the count. So to achieve the same guarantees we end up increasing the number of iterations (by a factor $>100$ ) and thereby the runtime.
After seeing Zhao et al paper we did some calculations and ran some simulations suggesting that sparse-XORs won’t work in practice. In the next section we describe major results from the paper.
Other popular belief in SAT community was that sparse constraints could be used directly with ApproxMC. We show that’s not the case atleast from the analysis of Zhao et al.
Major Results
1.) Spaesecount2: A better version of Sparsecount based on prefix-slicing
Prefix-slicing is a technique that uses prefixes of previous hash functions, thereby making them dependent. This dependence creates a ordering which could to perform Galloping Search( similar to Binary Search). Thus reducing the number of SAT oracle calls from linear to logarithmic.
$ n \rightarrow \log(n)$
This was the idea that made ApproxMC3 much faster than ApproxMC. We applied to SparseCount and obtained significant speedups(> 2.5x).
Code:
Release: Contains a prebuilt static binary
Github Repo: Contains the SourceCode
2.) Argument for why sparse XORs cannot be used with ApproxMC
It turns out the properties of sparse hash families proposed by Zhao et al are not sufficient for proofs of ApproxMC3 to go through. The proofs of ApproxMC3 depend on the relationship between variance($\sigma^{2}$) and mean($\mu$), specifically for proofs to work out $\sigma^{2} \leq \mu^{2}$. But with proposed family of hash functions it could be shown that $ \sigma^{2} \leq \eta $ where $\eta$ $\in$ $\Omega(\mu^{2})$.
3.) Empirical results supporting our arguments
All four algorithms, SparseCount, SparseCount2, ApproxMC, and Toeplitz-ApproxMC implemented in C++ and use the same underlying SAT solver, CryptoMiniSAT.
- Our algorithm SparseCount2 is 2.5x faster than Zhao et’al’s SparseCount.
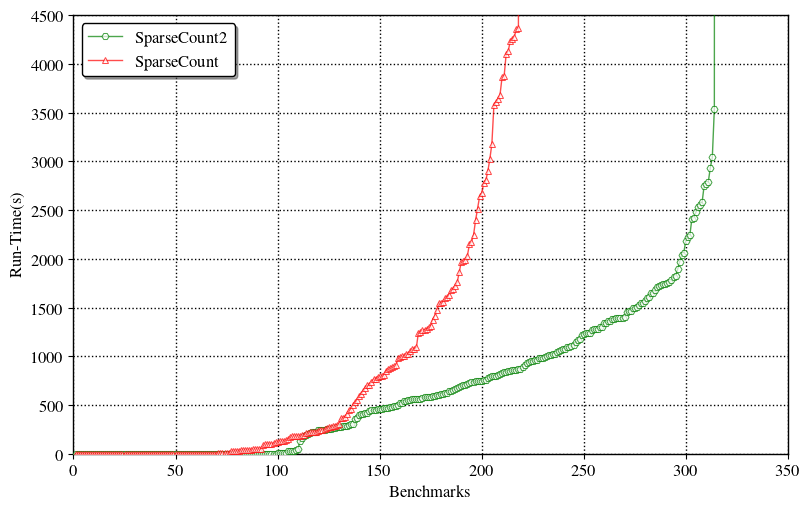 |
|---|
| SparseCount vis-a-vis SparseCount2 |
- Also the usual ApproxMC3 (with p = 1⁄2) is 118x faster than SparseCount.
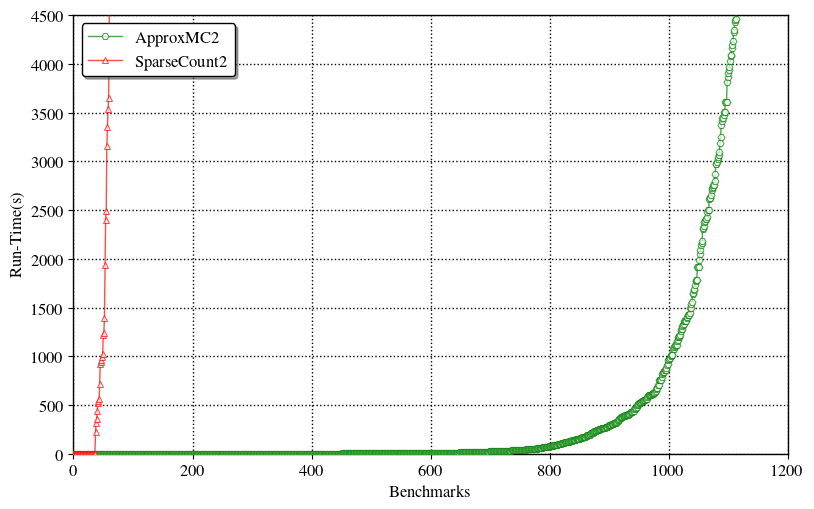 |
|---|
| ApproxMC3 vis-a-vis SparseCount2 |
Effect of Randomness
It was proposed by Ermon et al that usage of Toeplitz matrix where all the entries are not independent leads to more deterministic and stable behavior in their hashing-based algorithm for approximate weighted model counting, also known as discrete integration. We tried an implementation based on Toeplitz matrix to see if it has any effect. Note that usage of Toeplitz matrices bring down requirement of random bits from $O(mn)$ to $O(m+n)$.
We observe that there is no visible effect.
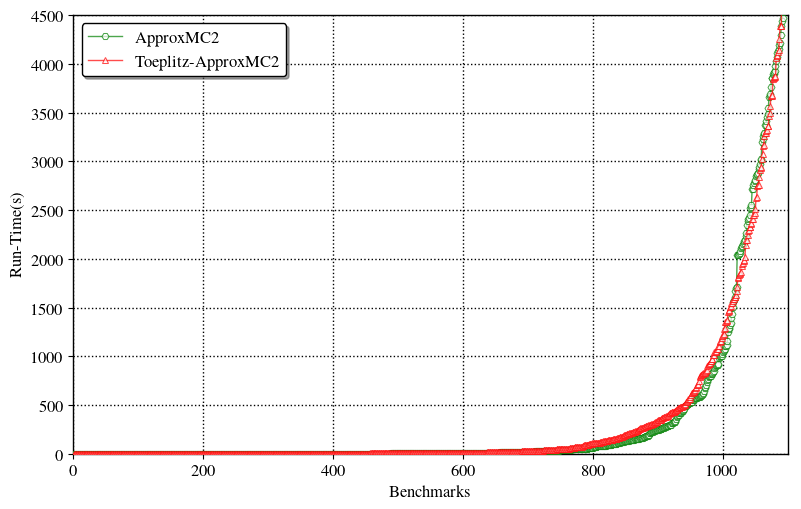 |
|---|
| ApproxMC3 vs Toeplitz-ApproxMC3 comparison |
Conclusions
Hashing-based techniques have emerged as a promising paradigm to attain scalability and rigorous guarantees in the context of approximate model counting.
The core idea of a hashing-based framework is a combination of SAT solving and usage of random XOR constraints to partition the solution space.
Since the performance of SAT solvers was observed to degrade with increase in the size of XORs, efforts have focused on the design of sparse hash functions .
Our conclusions are surprising and stand in stark contrast to widely believed beliefs that current construction of sparse XORs (by Zhao et al. and Ermon et al. ) lead to runtime improvement specifically we observe that
- Sparse constraints do not work with ApproxMC3.
- Sparsecount2 performs better than SparseCount
- ApproxMC3 performs much better than both SparseCount and Spaesecount2
- Toeplitz matrices have no effect on run-time
[1] You can find a nice blogpost , with much more SAT solver internal details, on the same here.
